Wat is een robots.txt bestand?
Een “robots.txt” is een tekstbestand dat ervoor kan zorgen dat niet alle pagina’s weergegeven of gecrawld worden in de zoekresultaten. Dit wordt bereikt door in te stellen wat de zoekrobots wel of niet mogen bekijken. Het doel is om met deze instructies de crawlers te laten weten wat ze wel en niet kunnen volgen.
Er kunnen verschillende redenen zijn om bepaalde delen van een website te beperken, dit zijn de voornaamste:
-
Crawlbudget sparen
-
De crawlbot meteen naar de belangrijkste links sturen
Het is een slimme manier om aan Google (of andere zoekmachines) te vertellen wat wel en niet belangrijk is op jouw website om geïndexeerd te worden. Robots.txt is een belangrijk onderdeel van je technische SEO. Indien je dit tekstbestand niet implementeert in je website, bestaat er een verhoogde kans dat ongewenste crawlers time-outs veroorzaken.
Waarom is een robots.txt belangrijk voor SEO?
Een goed geconfigureerde robots.txt is van essentieel belang voor een geoptimaliseerde website. Het voorkomt dat zoekmachines onnodige delen van je site crawlen, wat niet alleen de serverbelasting vermindert, maar ook je crawl budget beschermt.
Voordat de bot je website gaat crawlen, zoekt hij eerst naar het robots.txt bestand. Als de website dit bestand niet heeft, dan is zijn reflex om alle webpagina’s te crawlen. Dit kan een hele klus zijn, en neemt dan ook veel crawlbudget in beslag. Het kost Google tijd en moeite om alles te bekijken, wat hij dus niet van plan is. Maar de zoekmachine bot wil efficiënt en doeltreffend te werk gaan. En dat kan dus met je robot.txt bestand. JIJ beslist welke links Google moet volgen.
SEO gaat over het zichtbaar maken van jouw website voor de juiste doelgroep. Met een goed ingestelde robots.txt geef je belangrijke SEO pagina’s een indirect duwtje in de juiste richting, aangezien we vermijden dat er onnodige pagina’s gecrawld worden.
Hoe werkt een robots.txt?
Voordat een zoekmachine jouw website doorzoekt, raadpleegt de 'crawler' (bv. GoogleBot) als eerst het robots.txt-bestand. Hierin staan instructies welke delen van de website vermeden moeten worden. Het is een krachtige tool om deze crawlers in de juiste richting te sturen en ervoor te zorgen dat ze zich enkel richten op de relevante pagina’s.
Waarom zou je het gebruiken?
Eerst en vooral is het essentieel voor een geoptimaliseerde website. Het vormt een fundamenteel onderdeel van de technische SEO-audit, waarbij de ‘back-end’ van de website wordt geanalyseerd en aangepast. Het neemt inderdaad wat tijd in beslag om deze zo goed mogelijk te optimaliseren, maar de tijdsinvestering in het afstemmen hiervan betaalt zich terug in termen van zoekmachine zichtbaarheid en geeft een boost aan je indexering.
Beperkingen van Robots.txt
Allereerst garandeert Google niet dat het de regels die beschreven staan in de robots.txt wel degelijk zal volgen. Je kan het eerder zien als een verzoek dan als een bepalende regel. Houd dan ook in je achterhoofd dat, ondanks het invullen van de robots.txt, het toch mogelijk kan zijn dat klanten of andere belanghebbenden onbedoeld toch op de verkeerde pagina terechtkomen.
Een sitemap en andere onderdelen in robots txt
Sitemaps
Doordat iedere crawler de robots.txt doorneemt, kunnen we hier makkelijk onze sitemap linken. Op deze manier geven we meteen mee welke URL’s we het liefst zouden hebben dat hij gaat crawlen. Hierdoor is er een soort van ‘shortcut’, zodat de bot over de webpagina’s kan gaan.
Een sitemap is in de meeste gevallen niet statisch. Dit wil zeggen dat een sitemap, vanuit de regels van een robots.txt, wordt opgesteld en automatisch wordt opgesteld.
User agent
Een user agent is een synoniem van de zogenoemde ‘bot’ die langskomt. Er bestaan heel wat verschillende. Het is bekend van sommige dat ze belastend zijn of schade kunnen toebrengen aan de website. Het is dan ook een belangrijk onderdeel van je robots.txt. Via regelgeving kun je ze dan ook sturen. Bijvoorbeeld dat bepaalde user-agents, denk aan een GoogleBot, wel toegang hebben tot veel webpagina’s, maar dan andere slechts een gedeeltelijke of helemaal geen toegang hebben tot de webpagina’s. Denk maar aan bots van Yandex of Baidu.
Syntax in robots.txt
| Syntax symbool | Uitleg | Extra informatie |
| / | Deze schuine streep geeft aan dat alles dat na dit symbool komt, wordt opgenomen door de crawler. | |
| * | Dit teken werkt als een ‘wildcard’ of een 'joker', wat impliceert dat als het tussen twee URL’s wordt geplaatst, dit specifieke deel juist wel of niet wordt geaccepteerd. |
Zie bijvoorbeeld: Allow: ../*/… Disallow ../*/... |
| $ | Als dit teken in de regel staat, wordt het als het laatste teken toegevoegd. Indien het eerder geplaatst staat, heeft dit geen zin, omdat het bedoeld is om het einde van een URL-pad te benadrukken. | |
| # | De hashtag dient om commentaar toe te kunnen voegen voor de menselijke lezer (zie meer info onderaan). |
Een toepassing op de syntax van een robots.txt
We bekijken aan de hand van de robots.txt van WiSEO hoe de verschillende tekens hier gebruikt worden:
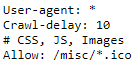
| Regel in robots.txt | Uitleg |
| user-agent: * | Alle user-agents die op de robots.txt komen, komen in aanmerking om de volgende stappen te ondernemen. |
| Craw-delay: 10 | Alles user-agents (zoals aangegeven hierboven), moeten na elke crawl 10 seconden wachten voor ze een nieuwe crawl kunnen uitvoeren. Dit dient voor User-agents die bekendstaan om veel aanvragen per keer, dit te doen verminderen. |
| # CSS, JS, Images | Dit is een opmerking dat volgende allows of disallows gaan over ‘CSS’, ‘JS’ en ‘Images’. Dit is een notitie en leest de crawler niet. Het dient namelijk als een opmerking voor de menselijke lezer. |
| Allow: /misc/*.ico |
Allow staat voor toestaan. Hiermee geef je dus aan welke tags gevolgd mogen worden en welke niet. In dit voorbeeld, mogen de pagina’s die ‘/misc/’ bevatten en eindigen op ‘.ico’ gecrawled worden. Dit betekent dat alles wat hiertussen kan en mag worden opgenomen in de robots.txt of een sitemap. |
Voor je bovenstaande tekens wilt gebruiken (met uitzondering van ‘#’), schrijf je eerst je regel op in de robots.txt wordt er gebruikgemaakt van ‘allow’ of ‘disallow’.
Wil je dat de crawler de webpagina’s bezoekt? Schrijf dan ‘allow’.
Wil je dat de crawler dit niet doet? Schrijf dan ‘disallow’.
Bijvoorbeeld het volgende:
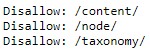
We nemen hier even het volgende uit: disallow: /content/
Dit wil zeggen dat we de crawler vertellen dat hij niet mag langskomen op een pagina die gevolgd wordt door /content/. Ook alles wat na de tweede slash staat, mag niet worden opgenomen.
Hashtag in robots.txt
Deze zijn bedoeld voor de menselijke lezer van de robots.txt. Het is een mededeling die de ontwikkelaar kan toevoegen. Ze bieden de ontwikkelaar de mogelijkheid om extra uitleg of instructies te geven over het tekstbestandje. Ze dienen als interne notities voor interne gebruikers. Dit geeft geen extra waarde voor de crawler, maar voor de menselijke gebruiker.
Hoe pas ik de robots.txt aan op mijn website?
Maar hoe moet dat nu? Lees het stappenplan hoe je zelf de robots.txt kan aanpassen.
Heel veel succes!





