
Afgelopen week ging de spring editie van BrightonSEO 2022 door in - je raadt het al - Brighton. En ik - Jan - was erbij. 2 dagen conferentie, 3 avonden mede-SEO specialisten spreken (en samen iets drinken). Je leert er wel wat van.
Het is mijn 5de conferentie en de 2e fysieke BrightonSEO. Ik weet uit vorige ervaringen dat je niet enkel op de talks moet focussen om bij te leren. Uiteindelijk gaat het erom dat praktische skills en inzicht kan verwerven om je dagelijkse job beter te doen. Daarom dat deze blog zal uitwijden in twee delen.
Deze blog capteert enkel de essentie & meest opvallende zaken van de talk. Da’s een voordeel en een nadeel. Misschien wil je de volledige presentatie doorspitten. Daarom vind je bij elke talk hieronder een link naar de volledige presentatie.
Inhoud
- Alle presentaties
- Bijzondere talks
- Mordy Oberstein - The full Scoop on Google’s Title Rewrites
- Benu Aggarwal - Entity Search Is Your Competitive Advantage
- Fili Wiese - Mastering robots.txt: SEO insights by an ex-Google engineer
- Jess Peck - How to build your own crawler, and why you should give it a try
- Shweti Prabhu - IndexNow, A paradigm shift in the search industry
- T. Mert Azizoğlu - SEO Automation Without Using Hard Code
- Michael Van Den Reym - Automate the technical SEO stuff
- Inzichten via andere SEO specialisten
- Slotwoordje
- Sfeerfoto's die je niet wil missen
Alle BrightonSEO presentaties
Jeroen Stikkelorum van YellowBlueMarketing maakte een zeer handig overzicht van alle beschikbare BrightonSEO presentaties.
Neem een kijkje.
Bijzondere talks
Mordy Oberstein: “The full Scoop on Google’s Title Rewrites”
Mocht je hem nog niet kennen, Mordy Oberstein is Head of SEO Branding bij Wix. Al sinds Augustus 2021 wordt door SEO specialisten opgemerkt dat Google zeer intens de titels (metatitel) herschrijft in haar zoekresultaten. Lily Ray pikte dit op (Twitter), Search Engine Journal begon erover te schrijven, en niet veel later bevestigde Google via een blogbericht dat ze inderdaad een nieuw system hadden geïntroduceerd dat geavanceerder titles herschreef in Google.
Mordy onderzocht de schaal hiervan, eventuele patronen, en wat dit voor ons betekent als SEO specialist.
Wat ons bijbleef:
-
Wat ze gebruiken: Wanneer Google je titel herschrijft, dan wordt vaak de H1 titel gebruikt.
-
Hoe ingrijpend: Wel eigenlijk is de titel voor 80% hetzelfde in 40% van de gevallen. Dus het gaat ook vaak over subtiele wijzigingen, zoals het vervangen van een scheidingsteken of weglaten/verplaatsen van je merknaam.
-
De patronen:
-
Lengte: geen correlatie. 1 tot 11 worden worden even vaak herschreven. Pas vanaf 12+ woorden wordt er veel vaker herschreven, maar dat valt ook te verwachten.
-
Positie: geen correlatie
-
Mobiel vs desktop: geen correlatie
- Zoekintentie: geen correlatie. Wanneer je kijkt naar de 4 basisintenties (informationeel, transactioneel, navigationeel, commercieel) dan zit er weinig verschil in.
-
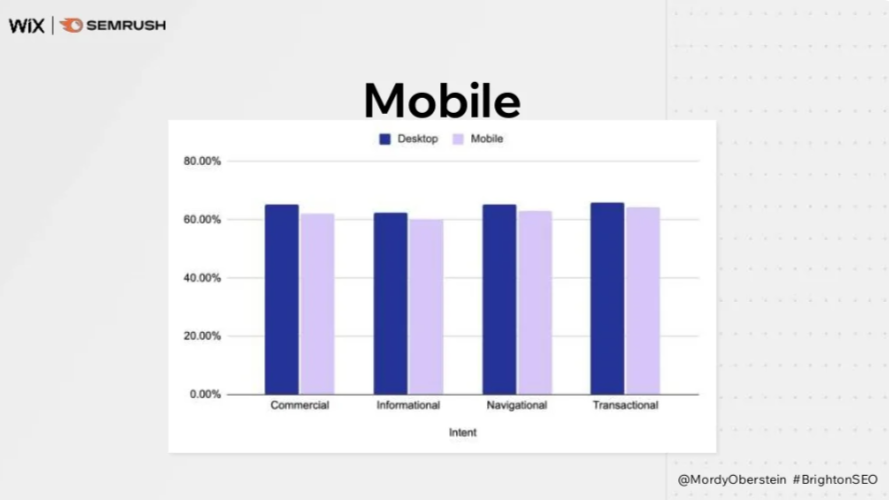
Conclusie?
Met andere woorden, er zit weinig structuur in. En dat verbaast ook niet. Er zijn wel bepaalde triggers maar je kan er moeilijk controle over krijgen omdat Google het volledig algoritmisch doet.
Één van die triggers die wij uit eigen ervaring met klantensites merken: Google haalt repititieve zaken weg uit titels. Bv. wanneer je “kopen aan lage prijs” of “kopen online” toevoegt aan élke titel van categorie of productpagina.
Gaat het dan altijd over kleine tweaks & straightforward zaken?
Vaak wel, maar er zijn cases te vinden waarbij Google wicked smart tewerk ging om de titel te herschrijven. Voorbeelden zijn onder andere het gebruik van een datum in de titel, die uit de URL werd geplukt. Maar er zijn ook andere redenen:
-
Geo-targeting: om een locatie duidelijk te communiceren
-
De nuttige info vooraan zetten
-
Duidelijke communicatie


Die laatste is bijzonder clever. Men zoekt online naar een dienst om paspoorten te hernieuwen en Google begrijpt dat zo goed dat ze er “County of San Diego” bijvoegden om verwarring weg te halen.
Een opvallende uitspraak die mij bijbleef: “If Google has enough confidence to rewrite your page title, then it has enough confidence that it understands your content.” Dus Google begrijpt de intent achter een zoekopdracht en de content op jouw pagina zo goed dat ze zelfzeker genoeg zijn dat ze jouw titel relevanter kunnen maken dan jijzelf.
Voor mij bewijst dat nog meer eens dat we al lang niet meer over “strings” maar over “things” spreken. Er zijn nog steeds SEO’ers die geloven dat je X aantal keer het zoekwoord in je tekst moet verwerken. Dat is geen ding meer. Het moet er natuurlijk wel een keer in vermeld staan, maar je tekst moet vooral zinnig zijn. Het moet een toegevoegde waarde hebben. Als je enkel van plan bent om te herschrijven wat ergens anders al op het web staat, dan is de kans dat je bovenaan in Google komt vrij klein. Ga dus voor nieuwe inzichten/informatie, aanvullend op de bestaande kennis.
Benu Aggarwal - Entity Search Is Your Competitive Advantage!
Benu besprak hoe entiteiten de toekomst van SEO vormen en je hierop kan inspelen. Een uitgebreide presentatie, maar ik geef de meest hapklare take-aways mee:
-
Visuals: Tag je afbeeldingen met attributen via schema
-
Het proces: Als je echt gefocust bent op je entiteit, dan is het zinvol om te beginnen met je schema, met je topics, e.d. Het design & effectieve tekst volgt nadien.
-
Ultieme takeaway:
-
Check Google en zoek de entiteiten die vandaag al aanwezig zijn.
-
Optimaliseer jouw content en voeg toe wat er volgens jou mist.
-


Fili Wiese - Mastering robots.txt: SEO insights by an ex-Google engineer
Geen presentatie beschikbaar
Fili is een veteraan bij BrightonSEO. In het verleden deed hij al meerdere talks en gaf ook opleidingen. Deze Brighton-editie ging zijn talk over de robots.txt en alle details waar je misschien niks van weet. Het draaide allemaal rond de zogeheten “Robots Exclusion Protocol” (REP).
Dit zijn mijn takeaways:
-
Elke “origin” kan een robots.txt hebben. In principe betekent het dat een verschil in de volgende elementen telkens als een aparte robots.txt wordt gezien:
-
FTP / LDAP
-
http/https
-
www, niet-www en subdomeinen
-
Poortnummers
-
-
Disallow geen paden die leiden tot gevoelige informatie. Dit wist je wellicht wel, maar het kan niet genoeg herhaald worden.
-
Dit wist je wellicht ook al, maar niet elke crawler of bot respecteert robots.txt. Als je een kwaadwillende speler wil blokkeren dan doe je dat best door het IP-adres of de User-agent te blacklisten (firewall bv.).
-
De user-agent in robots.txt is eigenlijk een identifier voor de volledige User-agent string (een token). Vandaar dat je User-agent: Googlebot kan schrijven terwijl de werkelijke user-agent string die Google gebruikt niet op één regel te schrijven is. Voor een overzicht bij Google kan je hier kijken.
-
Voor de User-agent worden cijfers niet geparset door Google. Dus MJ12Bot (Majestic) en 360spider zijn eigenlijk invalid. Toch vermoed ik dat de Majestic bot wel degelijk luistert naar die user-agent token. Maar volgens de documentatie: ‘t is fout :-)
-
User-agents kan je perfect bundelen door ze onder elkaar te zetten. Je hoeft de Disallow/Allow regels niet telkens te herhalen als ze hetzelfde zijn.
-
Misspellings:
-
User-agent: Google kan hier vrij goed mee om. Ze geven een waarschuwing.

-
Bij de Allow/Disallow: Let op, het is hoofdlettergevoelig (logisch ook).
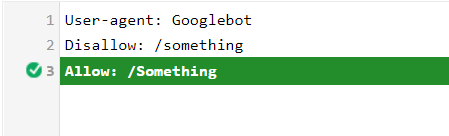
-
-
Vergeet volgende regels niet bij een allow/disallow:
-
Altijd starten met een slash
-
Disallow: map/submap (fout)
-
Disallow: /map/submap (juist)
-
-
Vergeet niet dat alles erachter ook matcht, dus volgende regels zijn hetzelfde
-
Disallow: /map/submap
-
Disallow: /map/submap*
-
-
Dit geldt ook voor extensies
-
Disallow: /*.css matcht dus ook met /bestand.css.png
-
-
Het pad is hoofdlettergevoelig, dus onderstaande is niet hetzelfde
-
Disallow: Index.php
-
Disallow: index.php
-
-
-
Non-group elementen
-
Sitemap
-
Noindex (niet meer in gebruik)
-
Crawl-delay (enkel Bing)
-
Clean-param (zeldzaam, maar gebruikt om parameters te negeren bij crawlen
-
-
Robots.txt heeft impact op crawling, maar niet op indexering. Dus simpelweg blokkeren via robots.txt betekent niet dat de pagina uit de index zal verdwijnen.
-
De regel van de least restrictive rule. Het minst restrictieve wordt toegelaten.

- De Longest match regel: Bij een conflict krijgt de langste regel voorrang.

- Robots.txt is een tekstbestand (text/plain), maar je kan dat perfect in HTML maken ook (text/html), zolang het in de broncode correct op aparte lijnen staat. Je vindt een voorbeeld op http://example.ai/robots.txt.
Is dit te veel om te onthouden?
Dat geeft niet. Je kan nog altijd de robots.txt tester van Google gebruiken om te testen. Dan ben je zeker.
Jess Peck - How to build your own crawler, and why you should give it a try
Als je begrijpt hoe een crawler werkt, dan begrijp je ook beter hoe Google werkt. Voila, dat is het. Daarom moet je dus een eigen crawler bouwen.
Maar het is ook gewoon leuk om te doen.
Ik raad aan om Jess haar presentatie te herbekijken hiervoor.
De takeaways:
-
Als je met Python aan de slag wil dan zijn Beautiful Soup (scraper) en Selenium (om te faken dat je een browser bent) dé tools die je nodig hebt.
-
Krijg je errors? Google ze. Voor elk probleem dat jij tegenkomt heeft ooit al eens iemand een ticket op StackOverflow geplaatst :-)
Shweti Prabhu - IndexNow – A paradigm shift in the search industry
Er is erg veel te doen geweest rond de nieuwe IndexNow API van Bing. Ik zag er het nut wel van in. Maar omdat initieel enkel Bing ervan gebruik maakte had ik mijn twijfels over de impact ervan.
Ondertussen is Google ook het gebruik van IndexNow aan het onderzoeken, en dat zou echt een gamechanger kunnen worden.
Toch is het nog steeds een “paradigm shift”, en wel om deze reden:
Nooit eerder heeft één zoekmachine - en ‘t is zelfs niet Google - mogelijk gemaakt om met één centraal mechanisme je website efficiënter te indexeren in meerdere zoekmachines.
Mocht het nog niet duidelijk zijn: Dit is een 1-op-meer relatie. Daar zit de kracht. Daarom ook dat IndexNow fantastisch zou zijn mocht Google het ook gaan gebruiken.
Als je wil weten hoe je IndexNow op jouw CMS of custom implementeert, raad ik aan om de slides eens 1 voor 1 te doorlopen.

T. Mert Azizoğlu - SEO Automation Without Using Hard Code
De presentatie begint met een deel over hoe Xpath, Google Sheets, Zapier & Screaming Frog kunnen helpen met automatisatie. Interessant om eens te bekijken.

Wat ik vooral heb onthouden, is dat je triggers kunt instellen voor het automatiseren van een script in Google Sheets.
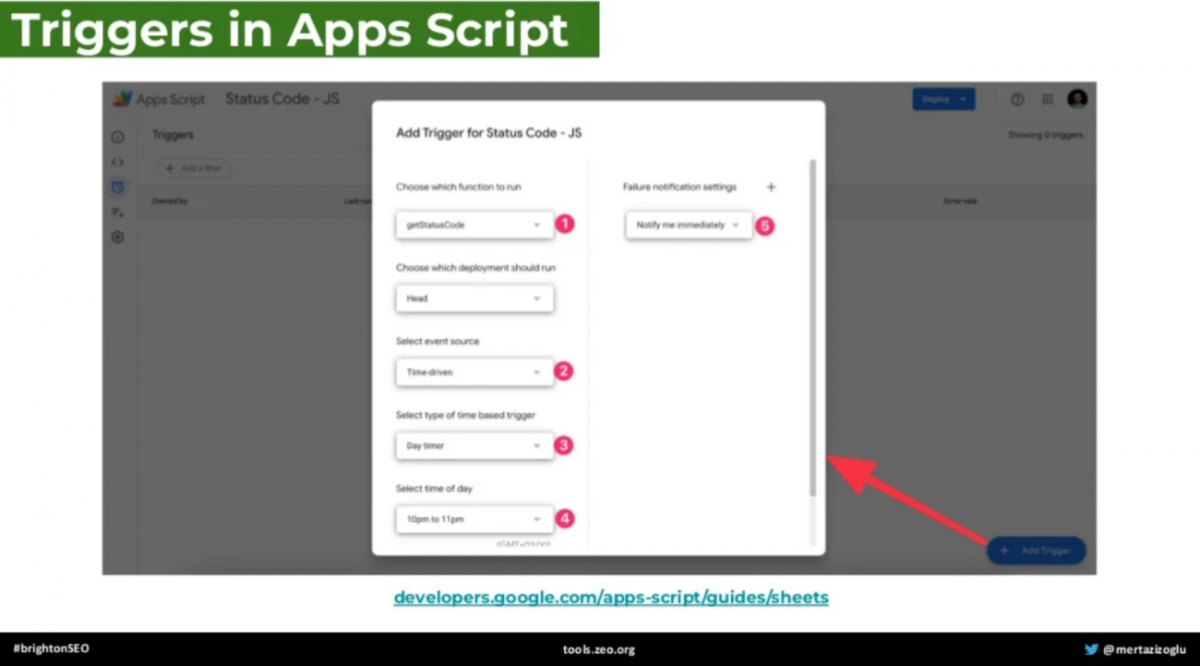
Interessanter zijn natuurlijk de use-cases, waar je gewoon een kopie kan nemen voor eigen gebruik of kan nabouwen.
Check periodiek alle URL’s uit een sitemap én controleer de status code (200 of 404?). Via Zapier kan je dat elke dag doen lopen én kan je een mail (alert) laten uitsturen naar je Gmail-adres wanneer er iets verandert.
Check rechtstreeks vanuit Google Sheets de status code van een heleboel URL’s.
Internal link catcher
Check alle pagina’s op je website voor vermelding van een zoekwoord in de tekst. Als het zoekwoord (waar een andere pagina voor geoptimaliseerd werd) in de tekst staat zonder link zal de tool die URL aangeven als interne linkopportuniteit. Dit kan je eigenlijk makkelijk via Screaming Frog automatiseren. Je hebt hier niet perse code voor nodig.
Robots.txt change detector
Via Zapier kan je alerts laten versturen wanneer de inhoud van de robots.txt verandert. Dit vind ik bijzonder interessant. Als je hiervoor een mail in je inbox ontvangt bij een wijziging kan je hier meteen op inspelen als het fout gaat. Mij lijkt dit ook mogelijk via Screaming Frog (scheduled crawl), maar dan kan je geen alert via e-mail versturen.
Je kan alle tools proberen op tools.zeo.org/sheets
Michael Van Den Reym - Automate the technical SEO stuff
Een bijzonder amusante en leerrijke presentatie van Michael over het automatiseren van SEO taken.
Automatisatie is technisch, maar dat betekent nog niet dat je het technisch moet brengen. Michael lichtte het nut toe adhv van een leuke video, waarbij robots moesten golfen en voetballen. Bij het golfen was de taak vrij duidelijk, niet ambigu en was er geen creativiteit nodig. Zoiets kan een robot wel. Maar wanneer robots tegen elkaar moeten voetballen, vallen ze om, maken ze fouten. Kortom, er komt creativiteit aan te pas, en dat kan een robot niet zo goed.
Het illustreert mooi dat automatisatie helpt bij saaie & repititieve taken, maar het is toch een uitdaging voor een robot om zelf creatief te zijn. Mensen zijn creatief, en kunnen heel creatieve zaken bouwen die schaalbaar zijn via automatisatie. Ik raad echt aan om de presentatie te herbekijken. Michael geeft 4 voorbeelden van creatieve automatisatie. Ik bespreek er hieronder één van.
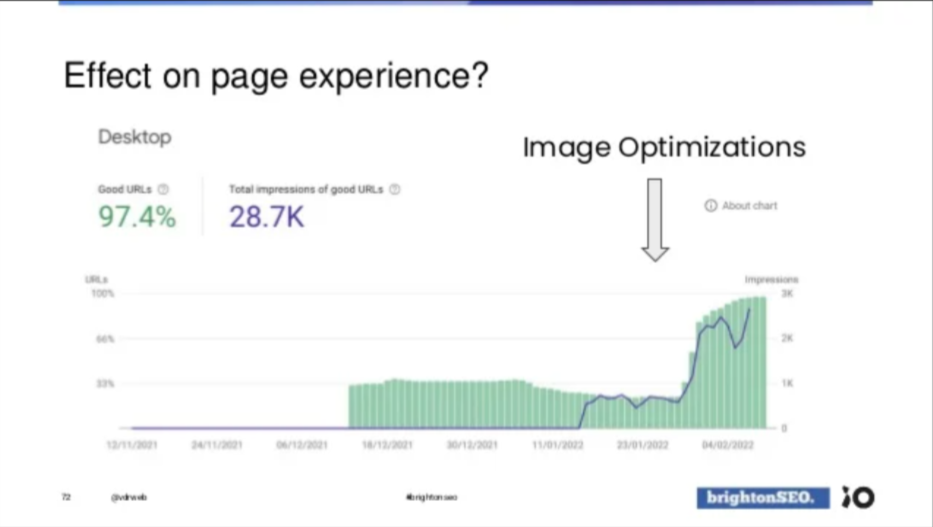
4. Image optimization
Ik bespreek deze omdat ik die bijzonder clever gedaan vind. Voor ovidias.com werd vastgesteld dat er erg veel foto’s te groot werden opgeladen op de website. De foto zou bv. 2000px breed zijn, maar nooit groter dan 500px gerenderd worden op het scherm.
Via Screaming Frog werden alle foto’s groter dan 100kB gedetecteerd en werden de inlinks naar die foto’s geëxporteerd naar een csv. De developer, noch de klant zag het zitten om al die foto’s (1.255 stuks) te herschalen. Can you blame them?
Hier komt de creativiteit naar boven. Met de Python library “pillow” maakte hij van àl die foto’s een kleinere, geoptimaliseerde versie. En om het de developer makkelijk te maken gebruikte hij voor de verkleinde afbeeldingen exact hetzelfde pad als de oude foto’s.
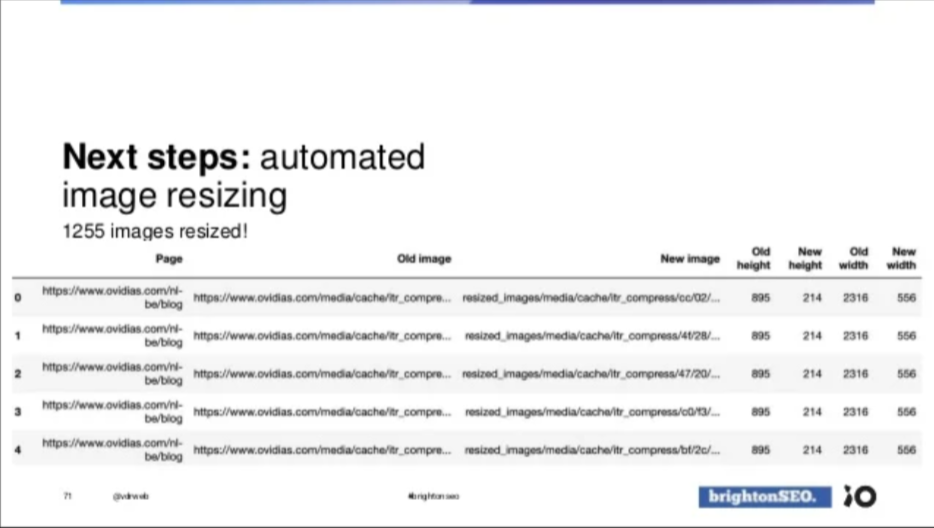
Het enige dat de developer nog moest doen, is de nieuwe foto’s opladen op FTP.
De impact? Wel:
Inzichten via andere SEO specialisten
Kijk je kan naar een conferentie gaan om bij te leren van de talks. En daar zitten best leerrijke tips tussen. Maar als je net zoals ik dagelijkse struggles wil oplossen, dan is er een betere & snellere manier. Praat met mede-SEO’ers en wissel ervaringen uit. Zeg hoe jij iets doet, en vraag hoe zij iets doen. Je gaat er veel praktische kennis uithalen die meteen inzetbaar is.
Marjolein Schollaert
Marjolein besprak met mij haar SEO-copywriting flow. Ik had een interessante discussie over hoe je agency vs. in-house die “contentmachine” in gang krijgt. Als je in-house werkt heb je daar een stukje voordeel omdat je dichter bij de business en bij de mensen staat. Maar dat hoeft je als agency niet tegen te houden.
Uit ons gesprek kwamen vooral volgende tips voort:
-
Als je een content audit maakt, zorg dan dat ze hapklaar is voor degene die ze moet omzetten in nieuwe teksten/pagina’s. Bij WiSEO werken we daarom met een “content skelet”. Wij geven al een suggestie mee voor metatitel, metabeschrijving, intro, alle ondertitels, hoe je een alinea start, etc. Maar de tekst zelf schrijven we nog niet.
-
Voorzie opleiding voor copywriters als het geen SEO copywriters zijn.
-
Het is beter om aan een constant tempo teksten/content te creëren zonder te veel te checken. Schrijf gewoon content voor je doelgroep in begrijpelijke taal obv de kennis die je online vindt.
-
Je tekst kan en zal zeker fouten bevatten, maar da’s niet erg. Het gaat erom dat het vooruit gaat. Bouw in je flow een feedbackmoment in met het legal team of met een product owner. Hij of zij moet je teksten inhoudelijk controleren op onjuistheden, tekortkomingen en kan aanvullingen voorstellen.
-
Om die flow te garanderen moet je dus wel goed afspreken op voorhand wie wat doet en wie bv. verantwoordelijk is voor die inhoudelijke check. Dat gaat niet vanzelf gaan.
-
De kracht hiervan is trouwens ook dat jij de ruwe structuur eerst uitzet als SEO specialist volgens de noden en vragen van de doelgroep. Dit in tegenstelling tot iemand die te diepgaande kennis heeft, met het risico dat je de essentie (en structuur) verliest in de details.
Tijs van Autreyve
Tijs is vrij vroeg begonnen met het implementeren van GA4.
Hij legde mij uit hoe je ruwweg met GA4 werkt en dat men onterecht claimt dat GA4 veel werk zou zijn. Denk aan het opnieuw toevoegen van tags bv. Maar eigenlijk kan dat vrij efficiënt als je gewoon een kopie neemt van de UA tag en de settings aanpast. De huidige trigger blijft geldig, de naam van de tag blijft geldig. Hij legde ook uit dat GA4 via een reeks parameters werkt en hoe je die kan gebruiken.
Slotwoordje
BrightonSEO is een fantastisch event om bij te leren over SEO. Ook dit jaar was het een geslaagde editie. Maar ik blijf erbij dat je niet enkel voor de sprekers naar Brighton gaat. Er valt ook buiten het conferentiegebouw veel te doen:
-
Mensen leren kennen: Shout-out Mathias Noyez, Jeroen Stikkelorum, Broes Sanders, Pepijn Otto, Marjolein Schollaert, Tijs Van Autreyve, Donald Martens en de mensen die ik nu teleurstel omdat ik je niet vernoem :-)
-
Iets gaan drinken: Een pintje bijvoorbeeld (NL: “een biertje”)
-
Samen iets gaan eten: Mexicaans, pizza, Thais, hamburgers. Aléja, typische gerechten uit de UK eigenlijk :-)
-
De pre- en afterparty: Waar je vooral elkaars zangkunsten leert kennen.
Sfeerfoto's die je niet wil missen










