
Een facetnavigatie kan heel wat schade toebrengen aan je SEO, maar hoe los je dit op?
Iedere Ecommerce website heeft er wel eentje, een facetnavigatie. Het helpt de gebruikers sneller te filteren en sorteren tussen de verschillende producten.
Alhoewel het zeer handig is voor de gebruikers, kan het een nachtmerrie worden voor de SEO van je website. Er kunnen duizenden onnodige URL’s geïndexeerd geraken.
Hoe gaan we Google aantonen wat geïndexeerd mag worden en wat zijn de voor en nadelen van deze oplossingen.
Wat is een facetnavigatie?
Even opfrissen, we definiëren een facetnavigatie als een manier waarop de gebruikers resultaten van een webpagina kunnen sorteren of filteren aan de hand van de eigenschappen van het product of de pagina. Bij een laptop zou dit de processor, kleur of type scherm kunnen zijn.
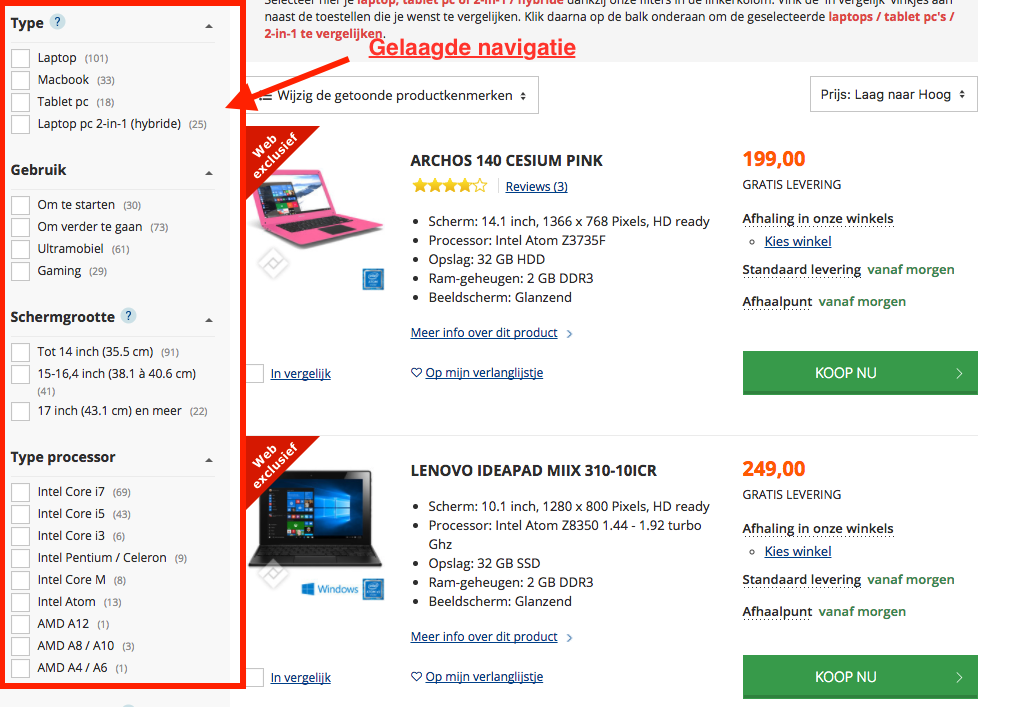
URL: https://www.vandenborre.be/computer-laptop/laptop-tablet-pc-of-2-in-1-hybride
Omdat elke mogelijke combinatie een unieke URL heeft, kan dit een groot probleem vormen voor SEO:
- Je creëert een hoop duplicate content
- Het slorpt je crawl budget op
- Het geeft linkwaarde aan pagina’s die we niet geïndexeerd willen
Enkele voorbeelden:
Zoekopdracht een Laptop van HP met 8GB ram tussen de 400 en 550 euro.
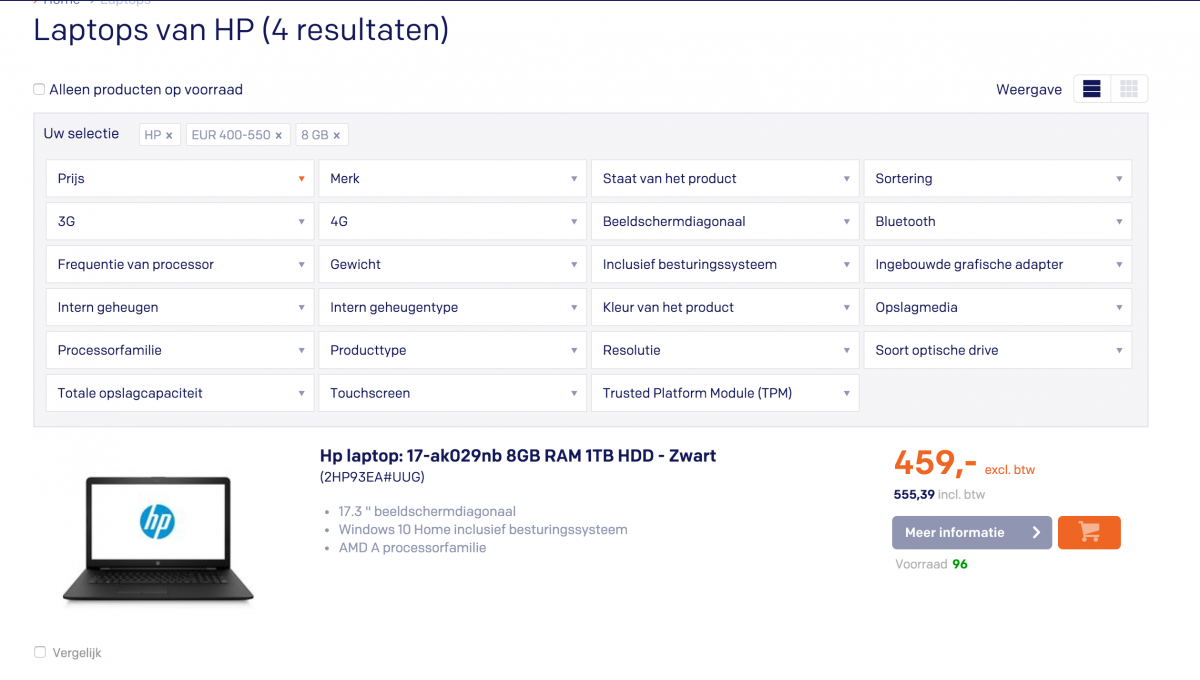
https://www.centralpoint.be/nl/laptops/?reset=1&priceRange=400-550&searchVendors=HP&facet_10980=8
Bij Centralpoint hebben ze er nogal een boeltje van gemaakt en dat niet enkel met hun Google reviews. Even snel zoeken in Google op ‘site:https://www.centralpoint.be/nl/laptops/?reset=1&priceRange=400-550&searchVendors=HP&facet_10980=8’ en we krijgen een totaal van 2.070 resultaten. Op deze manier verspild centralpoint zijn crawl budget aan 2.000 nutteloze pagina’. Wat ze wel goed doen is een canonical tag toevoegen aan de pagina's met te nauwe filters zodat ze hun linkwaarde kunnen doorgeven aan de pagina www.centralpoint.be/nl/laptops/.
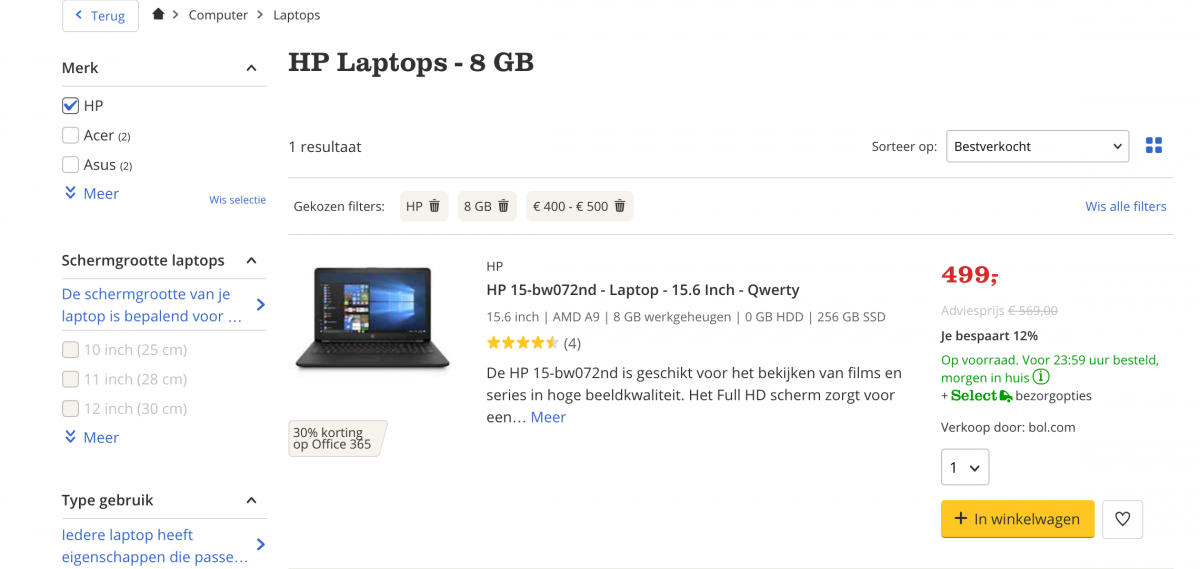
Bol.com doet het natuurlijk voorbeeldig op vlak van SEO en dat zie je hier ook terug. Wanneer we op de URL gaan zoeken in Google:
Google - "site:https://www.bol.com/nl/l/computer/laptops/N/4770/filter_N/4294864582+21584/filter_Nf/12194+BTWN+480+550/index.html"
0 resultaten
Breken we de URL af tot enkel het merk HP dan krijgen we enkel 1 resultaat.
Bol.com verliest door slim gebruik van de robots.txt dus geen crawlbudget op pagina’s die uiteindelijk dezelfde content hebben.
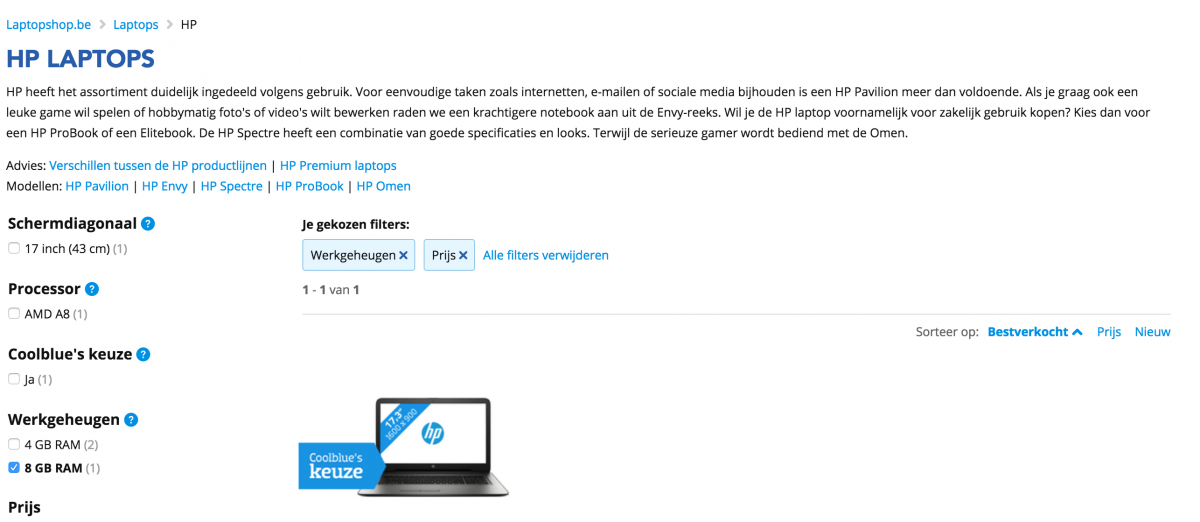
Zoals bij Bol.com krijgen we 1 resultaten wanneer we de URL opzoeken in Google.
Hoe los je dit op?
Er zijn verschillende oplossingen voor dit SEO probleem, maar elke oplossing heeft zo ook zijn voor-en nadelen natuurlijk. Wij lijsten ze even voor je op.
1. AJAX
Met behulp van AJAX gebeurt het filterproces in de achtergrond. Dit proces gebeurt op de client-side met javascript.
Zorg er wel voor dat er een HTML crawl pad is naar die pagina. Dit kan met het gebruik van de ‘pushstate‘ methode in de HTML history API en configureer de server voor deze aanvragen. Op deze manier bekom je een AJAX gestuurde navigatie zonder SEO-vriendelijkheid op te geven.
Het nadeel van deze methode is dat het veel tijd in beslag neemt om deze te implementeren en te testen.
Voordelen:
+ Gebruiksvriendelijk
+ Geen problemen met duplicate content
+ Clean url's
Nadelen:
- Implementatie kost meer tijd en dus ook geld
2. Meta Robots and Robots.txt
De meest betrouwbare manier om url’s te blokkeren is met behulp van de robots.txt. Het idee is om een aangepaste parameter op te stellen voor alle mogelijke combinaties (vb. “noidx=1”) en deze toe te voegen aan het einde van de URL die je wilt blokkeren.
Door onderstaande snippet toe te voegen aan de robots.txt kunnen we urls die de parameter "noidx=1" bevatten gaan uitsluiten:
User-agent: *
Disallow: /* noidx=1
Voeg de parameters (dynamisch) enkel toe aan te nauwe categorieën of aan pagina’s met twee of meer filters van hetzelfde kenmerk.
Hou rekening met volgende zaken:
Elke geïndexeerde pagina zou een unieke meta title, de hoofding en meta description moeten hebben en mogelijks ook inhoud.
Rangschik je URL altijd op dezelfde manier. Plaats niet de eerste keer "intern geheugen" op de eerste positie en een andere keer hem op tweede positie, ook als de gebruiker een andere volgorde kiest.
Voordelen:
+ Duplicate content opgelost
+ Bespaart op Crawlbudget
Nadelen:
- Linkwaarde wordt niet doorgegeven
- Geblokkeerde pagina's kunnen nog steeds geïndexeerd worden
3. Indexatie bepalen met rel="canonical"
Deze methode is het makkelijkst van de drie. Het zal je helpen om duplicate content te vermijden maar je bespaard hierbij niet op je crawl budget. Het voordeel van deze manier is dan wel dat je linkwaarde kan doorgeven aan belangrijke pagina's terwijl je met de robots.txt deze gewoonweg gaat blokkeren.
Ook worden canonical tags af en toe eens genegeerd door zoekmachines en zou je deze dus moeten gebruiken in combinatie met andere methodes.
Voordelen:
+ Duplicate content vermijden
+ Linkwaarde wordt doorgegeven
Nadelen:
- Nog steeds crawl budget verspilling
4. Google Search Console
Alhoewel deze tools kan helpen bij het oplossen van de tijdelijke problemen terwijl je aan betere navigatie bouwt, toont het enkel hoe Google je pagina crawlt en zou het dus als laatste optie gekozen moeten worden.
Met URL parameters tool in de Console, kun je zien wat het effect is van die parameters voor bepaalde pagina's en hoe Google deze pagina behandelend.
Let op: Deze manier werkt enkel voor de Googlebot en dus niet voor Bing of Yahoo agent-users
Voordelen:
+ Duplicate content vermijden
Nadelen:
- Worden niet altijd gevolgd door Googlebot
4. Nofollow op interne links naar ongewenste Facets
In dit geval plaatst men op de filters een 'nofollow' waardoor Google deze in principe niet meer zal volgen. Niet de beste oplossing want wanneer Google op andere pagina of site een link vind naar die pagina, crawlt hij die toch.
Voordelen:
+ Crawl budget
+ Heeft waarde van externe links door
Nadelen:
- Duplicate content
- Interne linkwaarde niet behouden
- Linkwaarde wordt niet doorgegeven
Wat gebruik ik nu best?
De manier waarop je dit moet aanpakken is voor elke website verschillend. Het hang sterk af van de manier waarop je navigatie is opgebouwd. Bij de meeste webshops hanteren wij volgende werkwijzen:
Geen filter:
index + <link rel=”canonical” href=”https://www.site.be/schoonheid/bruinen-zonder-zon” />
Vanaf 1 filter:
url --> https://www.site.be/schoonheid/bruinen-zonder-zon?fq%5Bbrand%5D=Bioderma
<meta name="robots" content="NOINDEX,FOLLOW" />
+ geen canonical want zorgt voor conflict met noindex.
Op termijn kun je er dan voor kiezen om toch enkele filters toe te laten wanneer je merkt dat hier vaak op gezocht wordt. Ik denk maar aan de combinatie van een categorie en merk (Samsung TV, Maybeline nagellak) of een bepaalde specificatie (3GB ram laptop, 47inch TV)
Enkele tips voor je aan een facetnavigatie begint of hem wilt aanpassen:
- Vermijd dat bezoekers een bepaalde categorie of filter kunnen aanklikken wanneer er geen producten aanwezig zijn die ertoe behoren.
- Elke pagina zou naar de hoofd-en subpagina moeten linken (mogelijks met breadcrumbs). Je kunt ook linken naar gelijkaardige pagina’s.
- Strikte ordening van je URL.
- Indexatie toelaten voor bepaalde combinaties die een hoog aantal bezoekers krijgen.
- Configureer de URL parameters in Google Search Console, maar zoek ondertussen naar een betere oplossing.
- Vertrouw niet volledig op noindex & nofollow. Je crawl budget wordt er niet mee gespaard.
- Enkele parameters zouden nooit geïndexeerd mogen worden.





